Moving slow operations to background jobs seems simple. Create a job class, call perform_async, done. Then production happens.
Jobs fail silently. Duplicate charges hit customers. The retry queue grows to 50,000 jobs. Deployments cause data corruption. I've seen all of these.
Sidekiq is battle-tested infrastructure—it processes billions of jobs daily across thousands of companies. But writing reliable jobs requires understanding how Sidekiq actually works and designing around its guarantees (and lack thereof).
The One Thing You Must Understand
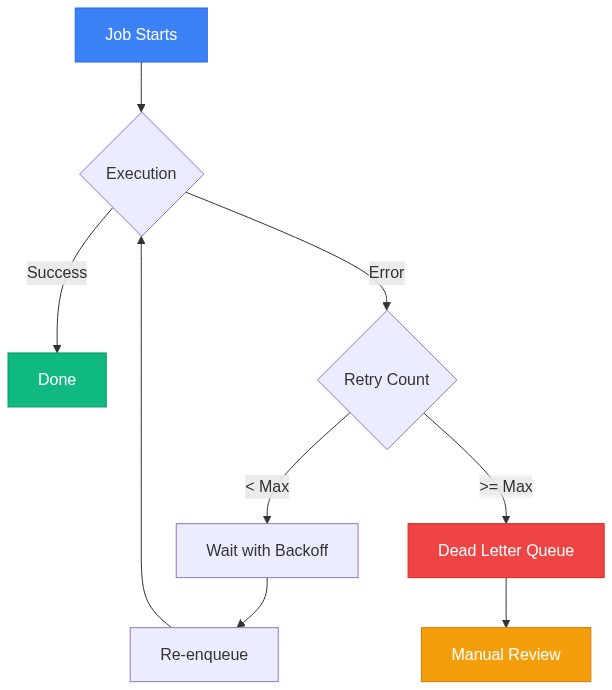
Sidekiq guarantees your job will run at least once. Not exactly once. At least once.
This means your job might run twice, three times, or more. Redis can crash after your job completes but before Sidekiq acknowledges completion. Network blips happen. Deploys restart workers mid-job.
If your job charges a credit card, it might charge twice. If it sends an email, duplicate emails. If it creates a database record, duplicate records.
The solution: design every job to be idempotent. Running it once or five times should produce the same result.
Idempotency Patterns That Work

Pattern 1: Check Before Acting
The simplest approach—check if the work was already done:
class SendWelcomeEmailJob
include Sidekiq::Job
def perform(user_id)
user = User.find(user_id)
# Guard: already sent?
return if user.welcome_email_sent_at.present?
UserMailer.welcome(user).deliver_now
user.update!(welcome_email_sent_at: Time.current)
end
endThis works but has a race condition. Two workers could both pass the guard before either updates the flag.
Pattern 2: Database Constraints
Use unique constraints to make duplicates impossible:
class ProcessPaymentJob
include Sidekiq::Job
def perform(order_id, idempotency_key)
order = Order.find(order_id)
# Create payment record with unique constraint on idempotency_key
payment = Payment.create!(
order: order,
idempotency_key: idempotency_key, # unique index
amount: order.total,
status: 'pending'
)
result = PaymentGateway.charge(
amount: order.total,
idempotency_key: idempotency_key # Stripe also supports idempotency keys
)
payment.update!(
status: result.success? ? 'completed' : 'failed',
gateway_id: result.id
)
rescue ActiveRecord::RecordNotUnique
# Already processed, safe to ignore
Rails.logger.info("Payment already processed: #{idempotency_key}")
end
end
# Enqueue with unique key
ProcessPaymentJob.perform_async(order.id, "order-#{order.id}-payment-#{SecureRandom.hex(8)}")The database constraint guarantees only one payment processes, regardless of how many times the job runs.
Pattern 3: Idempotent State Machine
For multi-step processes, use explicit state transitions:
class FulfillOrderJob
include Sidekiq::Job
def perform(order_id)
order = Order.find(order_id)
case order.status
when 'paid'
reserve_inventory(order)
order.update!(status: 'inventory_reserved')
FulfillOrderJob.perform_async(order_id) # Re-enqueue for next step
when 'inventory_reserved'
create_shipment(order)
order.update!(status: 'shipped')
when 'shipped'
# Already complete, nothing to do
Rails.logger.info("Order #{order_id} already shipped")
else
Rails.logger.warn("Order #{order_id} in unexpected state: #{order.status}")
end
end
private
def reserve_inventory(order)
# Idempotent: check if already reserved
return if InventoryReservation.exists?(order_id: order.id)
order.line_items.each do |item|
InventoryReservation.create!(
order_id: order.id,
product_id: item.product_id,
quantity: item.quantity
)
end
end
def create_shipment(order)
return if order.shipment.present?
Shipment.create!(order: order, status: 'pending')
end
endEach state transition is idempotent. The job can restart at any point and resume correctly.
Argument Best Practices
Pass IDs, Not Objects
Never serialize Ruby objects into job arguments:
# BAD: Object state gets stale
class BadJob
include Sidekiq::Job
def perform(user) # user is serialized at enqueue time
user.charge_subscription # Uses stale data!
end
end
# GOOD: Fetch fresh data
class GoodJob
include Sidekiq::Job
def perform(user_id)
user = User.find(user_id) # Fresh from database
user.charge_subscription
end
endSidekiq serializes arguments to JSON. By the time the job runs (seconds, minutes, or hours later), that user object's data is stale.
Use Simple Types Only
Job arguments must be JSON-serializable:
# GOOD: Primitives
MyJob.perform_async(123, "hello", true, 45.67)
# GOOD: Simple arrays and hashes
MyJob.perform_async([1, 2, 3], { "key" => "value" })
# BAD: Symbols (become strings)
MyJob.perform_async(:status) # Received as "status"
# BAD: Time objects
MyJob.perform_async(Time.current) # Serialization issues
# GOOD: ISO8601 strings for times
MyJob.perform_async(Time.current.iso8601)Handle Missing Records
Records can be deleted between enqueue and execution:
class ProcessUserJob
include Sidekiq::Job
def perform(user_id)
user = User.find_by(id: user_id)
unless user
Rails.logger.warn("User #{user_id} not found, skipping")
return
end
# Process user...
end
endOr use find and let ActiveRecord::RecordNotFound trigger a retry (if that's appropriate for your use case).
Retry Configuration
Default Behavior
Sidekiq retries failed jobs 25 times over about 21 days using exponential backoff:
Retry 1: ~32 seconds
Retry 5: ~10 minutes
Retry 10: ~2.5 hours
Retry 15: ~1 day
Retry 20: ~6 days
Retry 25: Dead queue (after ~21 days)
Customizing Retries
class CriticalJob
include Sidekiq::Job
# Retry more aggressively for critical jobs
sidekiq_options retry: 10 # Max 10 retries
def perform(id)
# ...
end
end
class NonCriticalJob
include Sidekiq::Job
# Don't retry at all
sidekiq_options retry: false
def perform(id)
# ...
end
end
class CustomBackoffJob
include Sidekiq::Job
sidekiq_options retry: 5
# Custom retry delay
sidekiq_retry_in do |count, exception|
case exception
when RateLimitError
60 * 60 # Wait 1 hour for rate limits
when NetworkError
10 * (count + 1) # Linear backoff for network issues
else
:exponential_backoff # Default behavior
end
end
def perform(id)
# ...
end
endHandling Specific Errors
class ExternalApiJob
include Sidekiq::Job
sidekiq_options retry: 5
# Don't retry certain errors
sidekiq_retries_exhausted do |job, exception|
Rails.logger.error("Job #{job['jid']} failed permanently: #{exception.message}")
NotifyOpsTeam.alert("Background job failed", job: job, error: exception)
end
def perform(record_id)
record = Record.find(record_id)
begin
ExternalApi.sync(record)
rescue ExternalApi::NotFoundError
# Record doesn't exist in external system, don't retry
record.update!(sync_status: 'not_found')
# Don't raise, job completes successfully
rescue ExternalApi::RateLimitError => e
# Retry with backoff
raise e
rescue ExternalApi::InvalidDataError => e
# Our fault, don't retry, fix the code
record.update!(sync_status: 'invalid_data', sync_error: e.message)
# Don't raise
end
end
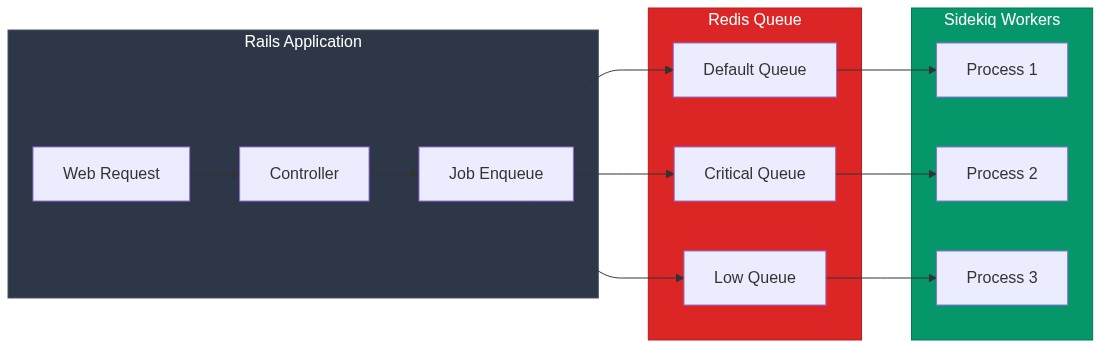
endQueue Organization
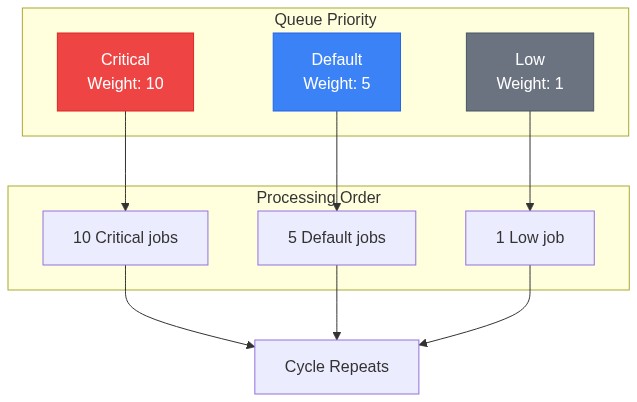
Separate Queues by Priority
# config/sidekiq.yml
:queues:
- [critical, 10] # Weight 10 - processed first
- [default, 5] # Weight 5
- [low, 1] # Weight 1 - processed last
# Job classes
class PaymentJob
include Sidekiq::Job
sidekiq_options queue: :critical
end
class ReportJob
include Sidekiq::Job
sidekiq_options queue: :low
endDedicated Queues for Slow Jobs
Long-running jobs can block other jobs in the same queue:
# config/sidekiq.yml - separate process for heavy jobs
:queues:
- heavy
# sidekiq_heavy.yml
:concurrency: 2 # Fewer threads for memory-heavy jobs
:queues:
- heavy
class VideoProcessingJob
include Sidekiq::Job
sidekiq_options queue: :heavy
endRun separate Sidekiq processes:
# Main process
bundle exec sidekiq -C config/sidekiq.yml
# Heavy jobs process
bundle exec sidekiq -C config/sidekiq_heavy.ymlDeployment Safety
The 25-Second Problem
During deployment, Sidekiq gets 25 seconds (configurable) to finish current jobs before being terminated. Unfinished jobs return to the queue and run again.
If your job takes 30 seconds and gets killed at second 20, it will restart from the beginning. If it's not idempotent, you have a problem.
Solutions:
- Keep jobs short: Break long jobs into smaller pieces
- Use checkpointing: Save progress and resume
- Increase timeout:
sidekiq_options timeout: 60
Checkpointing Long Jobs
class BulkImportJob
include Sidekiq::Job
sidekiq_options retry: 3
BATCH_SIZE = 100
def perform(import_id, offset = 0)
import = Import.find(import_id)
records = import.pending_records.offset(offset).limit(BATCH_SIZE)
return if records.empty? # Done
records.each do |record|
process_record(record)
end
# Re-enqueue for next batch
BulkImportJob.perform_async(import_id, offset + BATCH_SIZE)
end
private
def process_record(record)
# Process single record (idempotent)
return if record.processed?
# ... processing logic ...
record.update!(processed: true)
end
endIf the job gets killed mid-batch, it restarts from the same offset. Already-processed records are skipped.
Monitoring in Production
Essential Metrics
Track these in your monitoring system:
# config/initializers/sidekiq.rb
Sidekiq.configure_server do |config|
config.on(:startup) do
# Export metrics every 30 seconds
Thread.new do
loop do
stats = Sidekiq::Stats.new
StatsD.gauge('sidekiq.processed', stats.processed)
StatsD.gauge('sidekiq.failed', stats.failed)
StatsD.gauge('sidekiq.enqueued', stats.enqueued)
StatsD.gauge('sidekiq.retry_size', stats.retry_size)
StatsD.gauge('sidekiq.dead_size', stats.dead_size)
Sidekiq::Queue.all.each do |queue|
StatsD.gauge("sidekiq.queue.#{queue.name}.size", queue.size)
StatsD.gauge("sidekiq.queue.#{queue.name}.latency", queue.latency)
end
sleep 30
end
end
end
endAlerting Thresholds
# Example alerting rules
alerts:
- name: sidekiq_queue_backing_up
condition: sidekiq.queue.default.latency > 300 # 5 minutes
severity: warning
- name: sidekiq_retry_queue_growing
condition: sidekiq.retry_size > 1000
severity: critical
- name: sidekiq_dead_jobs
condition: delta(sidekiq.dead_size, 1h) > 10
severity: warningThe Sidekiq Web UI
Mount it in your routes (protected by authentication):
# config/routes.rb
require 'sidekiq/web'
authenticate :user, ->(user) { user.admin? } do
mount Sidekiq::Web => '/sidekiq'
endTesting Sidekiq Jobs
Inline Mode for Tests
# spec/rails_helper.rb
RSpec.configure do |config|
config.before(:each) do
Sidekiq::Testing.fake! # Jobs go to fake queue
end
end
# spec/jobs/send_email_job_spec.rb
RSpec.describe SendEmailJob do
it 'enqueues the job' do
expect {
SendEmailJob.perform_async(user.id)
}.to change(SendEmailJob.jobs, :size).by(1)
end
it 'sends the email' do
Sidekiq::Testing.inline! do # Execute immediately
expect {
SendEmailJob.perform_async(user.id)
}.to change { ActionMailer::Base.deliveries.count }.by(1)
end
end
endTesting Idempotency
RSpec.describe ProcessPaymentJob do
it 'is idempotent' do
order = create(:order, total: 100)
idempotency_key = "test-key-#{SecureRandom.hex}"
# Run twice
2.times do
ProcessPaymentJob.new.perform(order.id, idempotency_key)
end
# Should only create one payment
expect(Payment.where(order: order).count).to eq(1)
end
endPerformance Tuning
Concurrency Settings
# config/sidekiq.yml
:concurrency: 10 # 10 threads per processGuidelines:
- CPU-bound jobs: Match CPU cores
- I/O-bound jobs (API calls, DB): Higher concurrency (15-25)
- Memory-heavy jobs: Lower concurrency (2-5)
Connection Pooling
# config/database.yml
production:
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 }.to_i + ENV.fetch("SIDEKIQ_CONCURRENCY") { 10 }.to_i %>Each Sidekiq thread needs a database connection. Size your pool accordingly.
Batch Operations
Instead of many small jobs:
# SLOW: One job per user
users.each { |u| ProcessUserJob.perform_async(u.id) }
# FASTER: Batch processing
users.each_slice(100) do |batch|
ProcessUserBatchJob.perform_async(batch.map(&:id))
endThe Bottom Line
Reliable Sidekiq jobs come down to three principles:
- Assume jobs run multiple times: Design for idempotency from the start
- Keep jobs focused: One job, one responsibility, fast execution
- Monitor everything: You can't fix what you can't see
Sidekiq handles the hard distributed systems problems—retries, persistence, concurrency. Your job is to write code that works correctly regardless of how many times it runs.
Start simple. Add complexity only when you have evidence you need it. A well-designed idempotent job beats a complex distributed transaction every time.